Log analysis
Often we have a need to analyze log to get some information about the application. ELK is the one of the possible solutions for this problem. The basic source of information is HERE.
Here is the picture showing how it may look like:
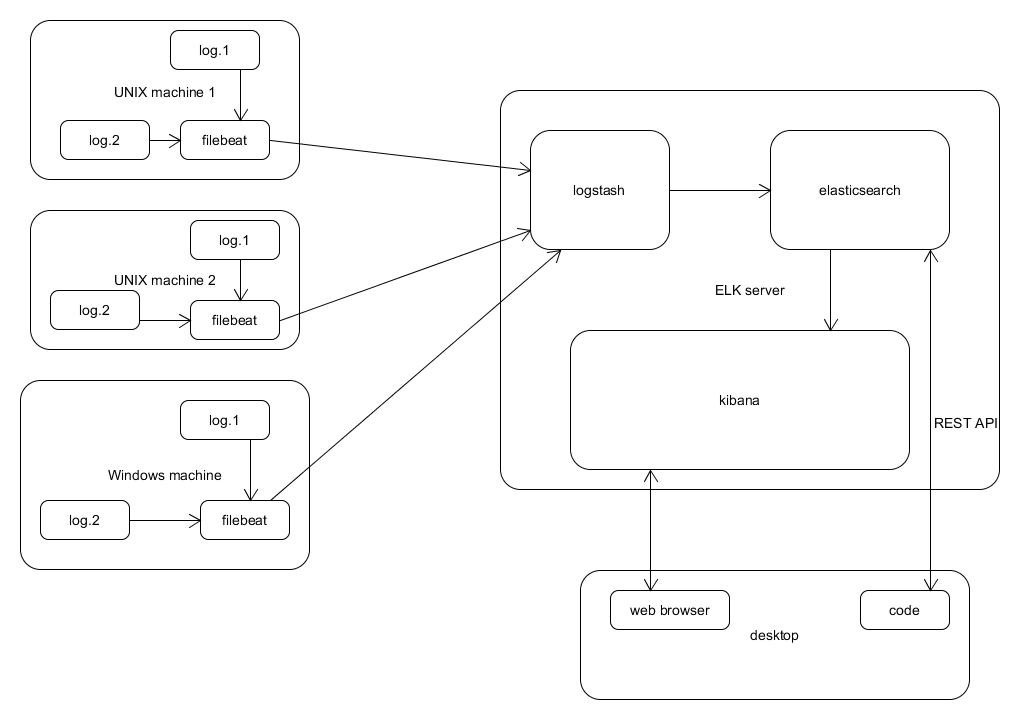
ELK architecture example
Filebeat – collects log data locally and sends it to logstash
Logstash – parses logs and loads them to elasticsearch
Elasticsearch – no-sql database – stores the data in the structure of “indexes”, “document types” and “types”; mappings may exist to alter the way given types are stored
Kibana – visualize the data
Desktop – user may use web browser to visualize data via Kibana or create a code to interact with elasticsearch via REST interface.
Besides installing and configuring all the stuff one needs to remember also about deleting old data in elasticsearch not to exceed disk space – logs can take huge amount of space as you know. I achieved that by creating some crontab started simple Perl script which parses index names and deletes the ones which are older than given amount of days. Automatic maintenance is a must for sure.
There is much in the web about Elk so I will not be giving any more details here. I would like to concentrate only on one thing which was hardest and took me longest time to achieve – logstash configuration.
Logstash
The documentation there on the page seems to be rich and complete, however for some reason it was very unhandy for me. Ok, I say more, the authors did the trick and created a page which was almost useless for me. I do not know exactly the reason but maybe it is because of too few examples, or maybe they assumed the knowledge of average reader is much higher than mine. Anyway, I needed really much time to achieve the right configuration for all items and especially for logstash.
Let’s get to the details now. Look at this configuration file:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 |
input{ beats{ port => 9000 } } filter{ if [type] == "logfile" { grok{ match => {"message" => "(?<date>[0-9]{2}\-[0-9]{2}\-[0-9]{2})%{SPACE}(?<time>\d{2}:\d{2}:\d{2},\d{3})%{SPACE}%{LOGLEVEL:loglevel}%{SPACE}%{GREEDYDATA:detailed_action}"} } grok{ match => {"message" => "(?<datetime>[0-9]{2}\-[0-9]{2}\-[0-9]{2}[ ]+\d{2}:\d{2}:\d{2},\d{3})%{GREEDYDATA:junk}"} remove_field => [ "junk" ] } date{ match => [ "datetime", "dd-MM-YY HH:mm:ss,SSS" ] timezone => "UTC" target => "datetime" } } if [type] == "testlogfile" { grok{ match => {"message" => "(?<date>[0-9]{2}\-[0-9]{2}\-[0-9]{2})%{SPACE}(?<time>\d{2}:\d{2}:\d{2},\d{3})%{SPACE}%{LOGLEVEL:loglevel}%{SPACE}%{GREEDYDATA:detailed_action}"} } grok{ match => {"message" => "(?<datetime>[0-9]{2}\-[0-9]{2}\-[0-9]{2}[ ]+\d{2}:\d{2}:\d{2},\d{3})%{GREEDYDATA:junk}"} remove_field => [ "junk" ] } date{ match => [ "datetime", "dd-MM-YY HH:mm:ss,SSS" ] timezone => "Europe/Warsaw" target => "datetime" } if [detailed_action] =~ /.*[a-zA-Z]+[ ]+[a-zA-Z]+.*/{ mutate{ add_field => {"detailed_action_notAnalyzed" => "%{detailed_action}"} } } } if [type] == "surefire" { mutate{ gsub => [ "message", "testsuite[ ]+name\=\"[a-z._]+", "testsuite name=\\\"", "message", "classname\=\"[a-z._]+", "testsuite=\\\"", "message", "\n", "", "message", "\r", "", "message", "\>[ ]+\<", "><", "message", "\t", ""] strip => "message" add_field => {"datetime" => "%{[@timestamp]}"} } xml{ source => "message" store_xml => "false" xpath => [ "/testsuite/@name", "test_suite", "/testsuite/@time", "time", "/testsuite/@tests", "test_suite_tests", "/testsuite/@errors", "test_suite_errors", "/testsuite/@skipped", "test_suite_skipped", "/testsuite/@failures", "test_suite_failures", "//testcase/@name", "testcase_name", "//testcase/@testsuite", "test_suite", "//testcase/@time", "time", "name(//testcase/*[1])", "status", "//testcase/*[1]/text()", "status_message", "count(//testcase/*[1])", "status_count" ] } if [status_count][0] == "0.0" and [testcase_name][0] =~ /.+/ { mutate{ update => { "status" => "pass" } } } mutate{ remove_field => [ "status_count" ] } } if [fields][arch_type] == "client"{ grok { match => {"source" => "%{GREEDYDATA:junk}\\%{DATA:junk2}(?<filename>[a-zA-Z0-9-]+\.[a-z]+$|[a-zA-Z0-9-]+\.[a-z]+\.[0-9]+$)" } remove_field => [ "junk", "junk2" ] } } if [fields][arch_type] == "server"{ grok { match => {"source" => "%{GREEDYDATA:junk}/%{DATA:junk2}(?<filename>[a-zA-Z0-9-]+\.[a-z]+$|[a-zA-Z0-9-]+\.[a-z]+\.[0-9]+$)" } remove_field => [ "junk", "junk2" ] } } checksum { keys => ["message", "datetime", "type"] } mutate { add_field => { "[@metadata][my_checksum]" => "%{[logstash_checksum]}" } remove_field => [ "logstash_checksum" ] } } # filter output { if [type] == "logfile"{ #stdout{ codec => rubydebug{ metadata => true }} elasticsearch{ hosts => ["localhost:9200"] manage_template => false index => "applicationName-%{+YYYY.MM.dd}" document_type => "%{[@metadata][type]}" document_id => "%{[@metadata][my_checksum]}" } } if [type] == "surefire"{ #stdout{ codec => rubydebug{ metadata => true }} elasticsearch{ hosts => ["localhost:9200"] manage_template => false index => "applicationName-test-reports" document_type => "%{[@metadata][type]}" document_id => "%{[@metadata][my_checksum]}" } } if [type] == "testlogfile"{ #stdout{ codec => rubydebug{ metadata => true }} elasticsearch{ hosts => ["localhost:9200"] manage_template => false index => "applicationName-test-logs" document_type => "%{[@metadata][type]}" document_id => "%{[@metadata][my_checksum]}" } } } |
- 1-5 lines are self explanatory – logstash receives input from filebeat
- 7+ – start of filtering data basing on the type which is defined there in the filebeat config (surefire will come from other machine, so no surefire document type here):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
filebeat: prospectors: - paths: - /path/logs/*.log input_type: log document_type: logfile fields: arch_type: server multiline: pattern: ^[0-9]{2}\-[0-9]{2}\-[0-9]{2} match: after negate: true tail_files: false ignore_older: 240h - paths: - /path/testlogs/*.log input_type: log document_type: testlogfile fields: arch_type: client exclude_lines: ["^#", "^$"] tail_files: false ignore_older: 240h output: logstash: hosts: ["hostname:9000"] shipper: logging: to_files: true files: path: beat_logs keepfiles: 3 |
- 12 – parsing of the line (seen under message variable by logstash) of which the example is: “01-01-16 13:05:26,238 INFO some log information”
now the mapping is created:
- date = 01-01-16
- time = 13:05:26,238
- loglevel = INFO
- detailed_action – “some log information”
- 17 – parsing “message” again to get datetime = 01-01-16 13:05:26,238
- 21-25 – date filter to explicitely set timezone to be UTC – this is important to have all the time date marked with proper timezone so that it can give proper results when analyzed afterwards
- 29-48 – it is the same for testlogfile type with one difference:
- 46 – this is how logstash can conditionally add field; when at least 2 words are encountered in detailed_action field, logstash will create duplicate of detailed_action named detailed_action_notAnalyzed (this is required when creating a mapping in elasticsearch which in turn allows to look for group of words – see the end of the post)
- 50-86 – surefire type which is interesting because it is xml data
- 52-60 – does 2 things: firstly is cleaning the input line from non-printable characters and extra white space and secondly it adds datetime field (logstash internal %{[@timestamp]} field is used); we don’t have datetime here as the opposite of the regular log data so we have to add it in logstash
- 61-78 – xml filter which maps xpath expression to field name, for example <testsuite “name”=”suite_name”> will turn into: test_suite = suite_name
- 79-84 – works around surefire plugin problem, that no status is shown in xml file when test cases passes, do you maybe know why somebody invented it this way? this is really frustrating and also stupid in my opinion…
- 87-96 – architecture type is checked here to determine filename (without full path), it comes from this place in filebeat config:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
filebeat: prospectors: - paths: - /path/logs/*.log input_type: log document_type: logfile fields: arch_type: server multiline: pattern: ^[0-9]{2}\-[0-9]{2}\-[0-9]{2} match: after negate: true tail_files: false ignore_older: 240h - paths: - /path/testlogs/*.log input_type: log document_type: testlogfile fields: arch_type: client exclude_lines: ["^#", "^$"] tail_files: false ignore_older: 240h output: logstash: hosts: ["hostname:9000"] shipper: logging: to_files: true files: path: beat_logs keepfiles: 3 |
- 101-104 – very important feature is here: the checksum basing on 3 fields is generated after which it is assigned to metadata field “my_checksum”; this will be used for generating document_id when shipping to elasticsearch which in turn allow to prevent duplicates in elasticsearch (imagine that you need to reload the data from the same server next day from rolling log files, you would store many duplicates but having checksum in place will allow only new entires to show up in database)
- 110-141 – output section which has type based conditions
- 116-118 – logfile document type will be sent to elasticsearch to index “applicationName-2016.05.26”, “logfile” document_type will be created with generated checksum document_id (to prevent duplicates)
- 112,122,132 – commented lines when uncommented serve for debug purpose: output is sent to elasticsearch and console at the same time
Other usage scenarios
After investing much effort in the solution I am also experimenting with other usage – not only for log data – to get more value in the project. After regression test suite is run I send surefire reports and test execution logs (this is domain language level) and view them via dashboard which also collects all application log data (server and client) at the same time. This gives consistent view on test run.
The interesting ability is also REST interface to elasticsearch. I use it for programmatically downloading the data, processing it and uploading the result back there. This is for the purpose of performance analysis where information in the log files as logged by the application requires processing before conclusions can be made.
This ability allows for example of creating very complex automatic integration or even system integration tests, where each component would know the exact state of the other by reading its logs from elasticsearch. Of course we should avoid complex and heavy tests (how long does it take to find a problem when system integration test fails…? ) but if you have a need of creating few of them at least it is possible from technical point of view.
In general…
… it is a nice tool. I would like just to name ELK drawbacks here – it is easier to find advantages in the web I think:
- it is hard to delete the data from elasticsearch so most often one needs to rely on index names
- logstash with complex configuration can start even 1 minute – any logstash configuration tests require separate logstash instance then
- it is hard to debug logstash
- there is no good way of visualizing the data in Kibana when you are not interested in aggregates; if there is some event logged, you can display information like how many times per day/hour/minute it occurs but you cannot do it like you would in gnuplot for example
- the search engine is illogic: to be able to find string like “long data log” one needs to have this fields stored as “string not analyzed field” (the default behaviour for strings is “string analyzed” when you can only search for single words); there is a trick to do the appropriate mapping in elasticsearch and store string as “analyzed” and “not analyzed” at the same time (if it is let’s say log_message “analyzed” string type, log_message.raw “not analyzed” variant is created at the same time) but kibana cannot work with *.raw fields; the mapping I am talking about looks like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
{ "template" : "index_name*", "mappings" : { "_default_" : { "dynamic_templates" : [ { "string_fields" : { "mapping" : { "type" : "string", "index" : "analyzed", "omit_norms" : true, "index_options" : "docs", "fields" : { "raw" : { "type" : "string", "index" : "not_analyzed", "ignore_above" : 256 } } }, "match_mapping_type" : "string", "match" : "*" } } ], "_all" : { "enabled" : true } } } } |
So, you need to split the log_message in logstash to create two separate fields (look at line 46 of logstash config discussed above) e.g. log_message and log_message_notAnalyzed. Otherwise to search for “long log data” string in kibana you have to write this thing:
|
1 |
log_message:long AND log_message:log AND log_message:data |
Which searches also for things you do not want to find: “log data long”, “log stuff stuff long stuff data”, “stuff long log stuff stuff data” etc. This is really a problem given the need of finding few word strings is very common thing.
That’s it for disadvantages. I think ELK does the job of log analysis very well anyway. For sure it is worth to try.