Pipeline
I am working nowadays on a pipeline improvement. This is absolutely crucial part of QA process in the project. Good pipeline is the core around which we can build all the things which constitute high quality.
When starting new project, create pipeline first!
But what does it mean a “good” pipeline? It has to be reliable, informative and it has to be really, really fast. That’s it.
What’s that?
Pipeline is the sequence of actions which should start with the code build and end with the tested build artifacts. There is a feedback about the code: is it OK or not OK? In case of OK message, the artifacts may be just deleted at the end altogether with test environments (continuous integration), may be released (continuous delivery) or – the most interesting option – may be deployed to production (continuous deployment).
There are strategies about the code management: for me the most basic classification is branchless development (some info HERE) vs branching one (well you know this one for sure). In case of the latter (most popular I guess) the successful pipeline allows the code to be merged into main branch, while unsuccessful pipeline prevents the defective code from merging anywhere. In case of the branchless approach immediate actions need to be taken as the code which doesn’t work as expected is already there in your code repository.
The pipeline can be implemented using dedicated software as Bamboo, TeamCity or open source Jenkins.
Jenkins
I will be describing Jenkins in this article as I have most experience with this application. As usual it is a piece of software which has advantages and disadvantages. If I was to name the biggest one item of both:
- biggest disadvantage – disastrous quality of the plugins’ upgrades: one can expect everything after the upgrade: usability change, feature disappear, old bugs come back (regression) etc.
- biggest advantage – great implementation of agents: each agent can have many executors which are very easy to configure; the scalability is therefore fantastic and allows massive number of concurrent jobs to be run as each of the job requires one free executor only; commercial competition doesn’t use executors and so 1 agent always means only 1 job at a time: it must be causing much bigger overhead when designing pipeline with many concurrent jobs on 1 machine in my opinion, as many agents are needed while Jenkins can use only 1 per machine.
The practical problems
I mentioned about reliability, information and performance.
- reliability – pipeline has to work in the same way every time it is launched; no IFs, no unexpected stopping, no deviations in terms of duration of the pipeline as well as amount of feedback information, the general goal is we have to be confident about the pipeline itself
- information – pipeline has to provide clear information what is working and what is not; clear information means we do not use any more than few seconds to know if the problem is related to module B of our Java application or maybe security problem with “user management” feature
- performance – pipeline has to be as fast as possible; the larger project the more hard it is to achieve, for me the nice result which I call “fast” is 10 minutes for build and all unit tests and 20 minutes for all the heavier tests (integration, GUI etc); total pipeline runtime of 15-20 minutes is fantastic performance, 20-30 is acceptable but improvements need to be found, >30 is poor and improvements just have to be found; it’s a psychology behind this: let’s do it 3 times per hour or at least twice: if we are waiting 35 minutes the magic disappears
It all sounds simple but it is really hard to achieve. In practice there is often a counterpart of the list above: pipeline gets stuck at random places (application doesn’t install on 1 environment?), it gives red/yellow/green statuses but no one knows what are they tied to (can I release the software or not? is it ok?) and finally it lasts for 2 hours which feels like forever (let’s commit only few times a day otherwise we will not be able to see the result – developers think).
There are many reasons of this:
- people’s mindset – they discuss every character in the code but forget about the pipeline
- pipeline software specific problems – in Jenkins there can be 2 kinds of jobs: created in GUI using a mouse clicks and stored inside Jenkins application or written in so called declarative (or older version: scripted) pipeline stored in files in CVS. If the jobs are GUI based they are impossible to maintain for a longer time as their number grows and the relations between them get more complicated. They start living their own life.
- traditional approach to the sequence of stages in the pipeline (all the stages are run in sequence)
- doing one universal job which does many things
- relying on software project management tool only (like Maven), to implement test concurrency and their reporting without using the features of pipeline software
- physical environments availability
- physical environments configuration
Fixing it (in details)
I would like to show some details in this section how to try to fix all the problems.
Squashing pattern
Let’s start with the general image of the pipeline. If there are stages/jobs run in the sequence like this:
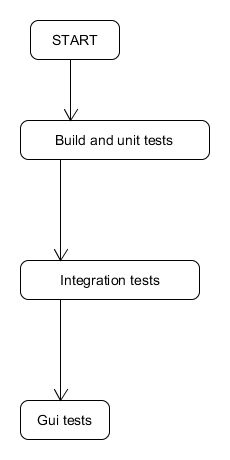
stages in the sequence
We need to squash it as much as we can, that is:
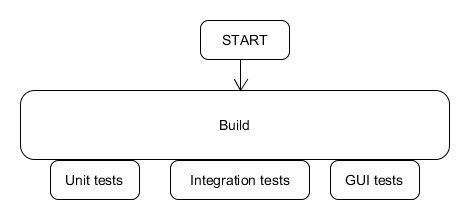
squashed pipeline
We need separate build stage to be able to use build artifacts for all the testing stages we need to do. We just need to build only once and use the output everywhere we need.
For Maven, it means the transition from notorious:
|
1 |
mvn clean install |
into 2-step:
|
1 2 |
mvn clean install -DskipTests=true mvn surefire:test |
1. line is then placed inside Build stage and 2. line is a Unit tests stage.
All other tests start at the same point of time as Unit tests. Of course, heavy tests like GUI require application redeployment. So the stage has to have separate section for redeployment, like this:

gui stage
But what is the redeployment step? We have numerous problems when dealing with this step very often. To achieve the stability we have to switch to virtual solution – Docker. Only then can we have the control on this step. If you do not know it yet for some reason read about it, otherwise start using it. It greatly improves the stability of the pipeline:
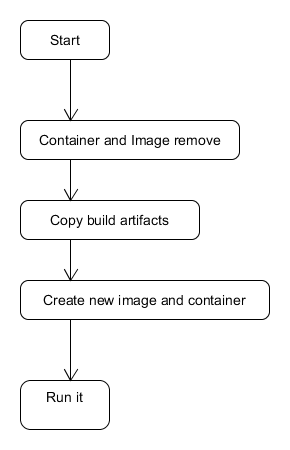
docker job
But what about the situation we need numerous redeployments for e.g. different applications configiurations? Then we just take advantage of parameters each of the jobs have. In Jenkins, each of the job consists of the stages. Each job can also receive and pass parameters. Again we modify the pipeline by introducing new job:
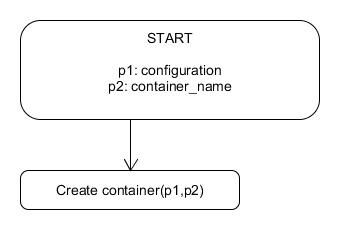
create container
Now, for each of the required application configurations we have instance of the create_container.job running.
As you can see, we have now stage for each logical step we make in our pipeline.
In general, the pattern is to drill down to the most logical atomic steps to visualize them in pipeline software and squash them as much as possible to gain performance.
Pipeline as code
In Jenkins, as I mentioned above, there is a possibility to click the jobs in GUI. Just do not do that! It is the dead end. The jobs become impossible to maintain very quickly and you are completely stuck. Use declarative pipeline instead.
In Jenkins you use Groovy to create scripts in a simple way like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
pipeline { parameters { string(name: 'MODULE_NAME', defaultValue: 'none', description: 'module name to process') } tools { mvn "maven_label_from_Jenkins" } stages { stage { steps { echo("I am 1. step !") sh "mvn clean install -DskipTests=true" sh "mvn surefire:test -pl ${params.MODULE_NAME}" } } } } |
The point is to have pipeline expressed in some language and store it in control version system (CVS). It applies also to any other software used for pipeline: if there is a possiblity to store pipeline as code, do it, otherwise change the software !
Moving away from project management tool like Maven
Let’s come back to the unit tests step. Unit tests are important stage but often long lasting one. Although we have separate stage for unit tests so far, we still have room for improvement there.
The usual attempt to increase the unit tests speed is:
|
1 |
mvn -T 8 clean install |
However I think it is wrong approach as this is moving the concurrency functionality away from pipeline software to Maven. Also, the performance gain is very much questionable. The better approach in my opinion is to ask pipeline software to do the job. It is required just to get the list of modules we need to test. We can do it using Maven:
|
1 |
mvn -Dexec.executable='echo' -Dexec.args='${project.artifactId}' exec:exec -q |
We need to create a job where 1. stage will be module list collecting stage and 2. stage will generate another stages for each of the individual modules. Here is a full example:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
pipeline { stages { stage(GET_MODULES) { script { env.MODULES = sh(script: "mvn -Dexec.executable=echo -Dexec.args=\$\\{project.groupId\\}:\$\\{project.artifactId\\} exec:exec -q", returnStdout: true).split("\n").join(",") } } stage(INVOKE_CONCURRENT_TESTS) { script { runConcurrent(env.MODULES.tokenize(",")) } } } } def runConcurrent(modules) { def stages = modules.collectEntries { module -> ["${module}": { node(env.AGENT) { stage("${module}") { dir(env.BUILD_ARTIFACTS_PATH) { sh "mvn -U surefire:test -Dmaven.repo.local=\"maven/repo/path\" -pl ${module}" } } } }] } parallel stages } |
This is a mixture of declarative pipeline and scripted pipeline which allows dynamic stage generation.
In the GET_MODULES stage we extract all the modules from our application and store them as string in env.MODULES variable (this is saved as string and then tokenized to create array). In the INVOKE_CONCURRENT_TESTS stage we generate the stages using runConcurrent method. Each stage will be named using module name.
There are 2 things we need to pay attention to.
The 1. one is workspace. Each generated stage has its own workspace so it cannot see the project which should be tested. To point each stage to the right one, dir directive has to be used represented here with env.BUILD_ARTIFACTS_PATH. I think the best pattern – used here – is to keep workspace with build artifacts available for each job (so that it can be accessed from any agent by dir directive). If this is not possible the stage which does the build needs to archive artifacts to Jenkins master and then each of the generated stages would have to copy them from there. This affects performance of the pipeline very significantly.
The 2. important thing is maven repo set by -Dmaven.repo.local parameter. It is easy to confuse things and run into trouble when default maven repository is used. Especially when building different software versions at the same time or building 2 different applications it is good thing to have dedicated maven repository for each of them.
Anyway, we have now each of the modules tested by separate stage and the duration of the tests is equal to the duration of the longest lasting module:
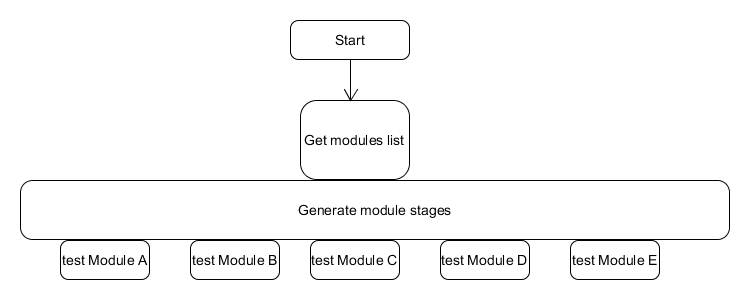
unit tests job
We can do it this way as we are dealing with unit tests – unit is something which is independent and so our tests must be running properly in this way. The huge performance gain is one point, the other is very clear feedback about the point of failure if one occurs.
Speaking about the clear feedback…
Clear feedback
The goal of this is to get to the point where pipeline provides clear information what is working and what is not. We have it unit tests job already. If module B fails we will know it immediately on the screen as there is separate stage dedicated to each of the modules.
But what about GUI tests? When the job fails, which feature is not working? We need to know it immediately as well, no time to search the logs! The answer is to group the GUI tests in a way that each group represents one of the business functionalities. Let’s imagine application under test has 3 significant features tested: security, processing and reporting. After the tests are grouped (for example in separate packages on the code side), it is possible to create a job like this:
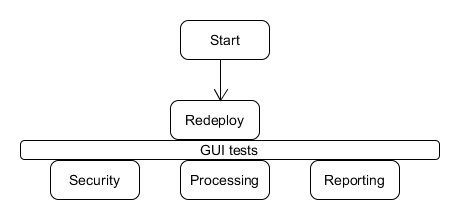
gui tests with features
In this job, all the tests are run concurrently, but when any of the groups fails we exactly know which business area is affected and we can make decisions about the quality of the current build.
Known defects or unknown ?
Very often – I would say too often – there is a situation, some defects exists but due to their priority or some other reasons they are not fixed immediately. They are present for very many builds and mark their presence with red colour. It completely blurs the image about the state of the application: is it ok? Or not? Does the red colour mean we have new defects or maybe these are known ones?
The solution of this problem is to introduce mechanism to mark the known failures in the pipeline software and to set the status accordingly. In Jenkins, it is possible to set status to yellow (unstable) or red (error). We need piece of software which scans through the reports (either Junit or testng report files) and puts the defect number inside the file on one side and set status accordingly on the other: when all the failures are known the status becomes yellow and if there is at least 1 unknown failure the status is red. Because the defect number is put inside the report file we can view it on the report page in Jenkins.
I didn’t find any out of the box solution for this so I created small application myself.
In details, let’s say we have junit report – we need to parse it for example with the help of great library JSoup I described here. We need to have some file containing mapping infromation that is class/method which is already reported and the ticket number. The code parses the junit XML report and substitutes all the known class/method occurences with the same name but with ticket number appended:
|
1 2 |
foo3:AFailingTest:#12345 foo5:AnotherFailingTest:#19283 |
|
1 2 3 4 5 6 7 |
<testsuite tests="3"> <testcase classname="foo1" name="ASuccessfulTest"/> <testcase classname="foo2" name="AnotherSuccessfulTest"/> <testcase classname="foo3" name="AFailingTest"> <failure type="NotEnoughFoo"> details about failure </failure> </testcase> </testsuite> |
|
1 2 3 4 5 6 7 |
<testsuite tests="3"> <testcase classname="foo1" name="ASuccessfulTest"/> <testcase classname="foo2" name="AnotherSuccessfulTest"/> <testcase classname="foo3" name="AFailingTest_#12345"> <failure type="NotEnoughFoo"> details about failure </failure> </testcase> </testsuite> |
Because of this ticket number can be displayed in Jenkins GUI. As the information about number of known failures is known the status turns green if no failures are found, yellow if only reported failures are found and red if there is at least 1 unknown failure in the report.
The final pipeline
After all these ideas are implemented we can see our final pipeline:
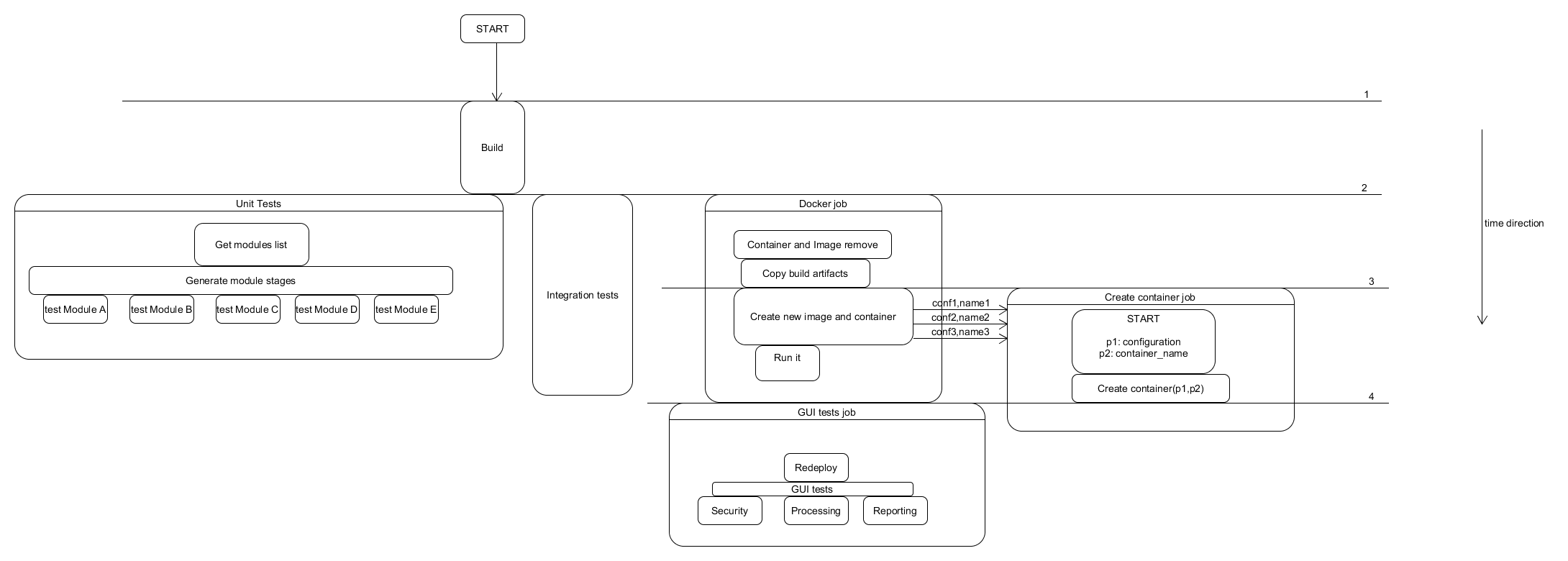
final pipeline
It is now squashed. It consists of atomic jobs which can be run as seperate units (for example for testing purposes). It gives fast and clear feedback. It is reliable and significantly improves the quality of the application under test.
Summary
I described here actions I am taking when dealing with the pipeline problem. I am sure this approach is universal: try to make pipeline reliable, clear in feedback and as fast as possible.