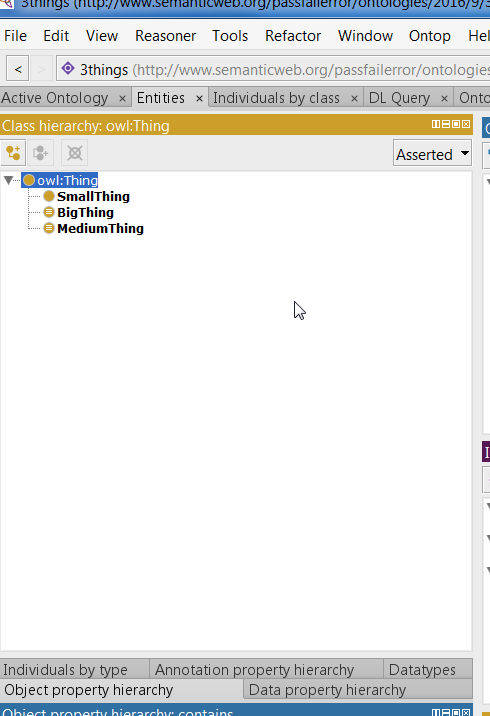
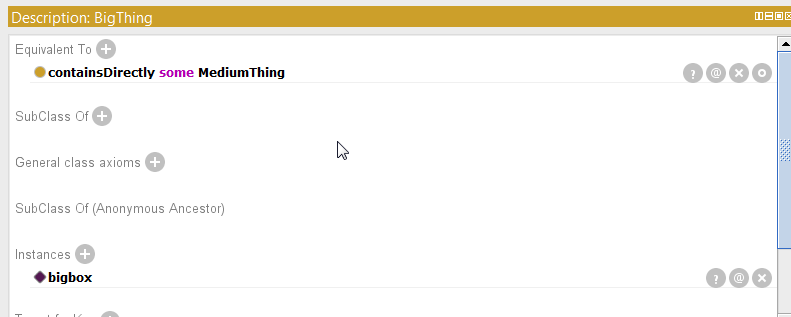
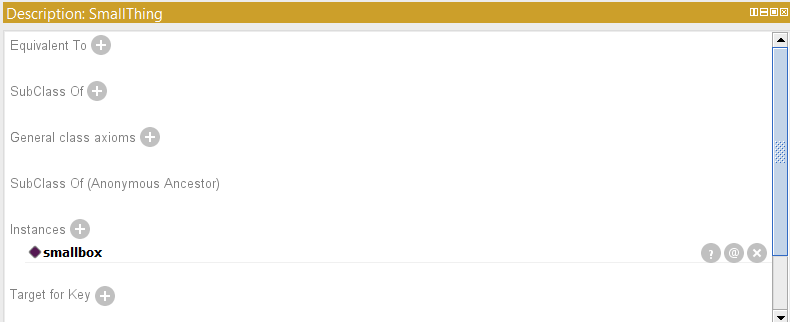
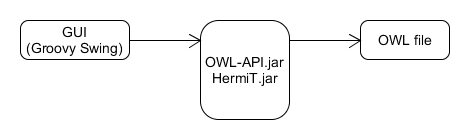
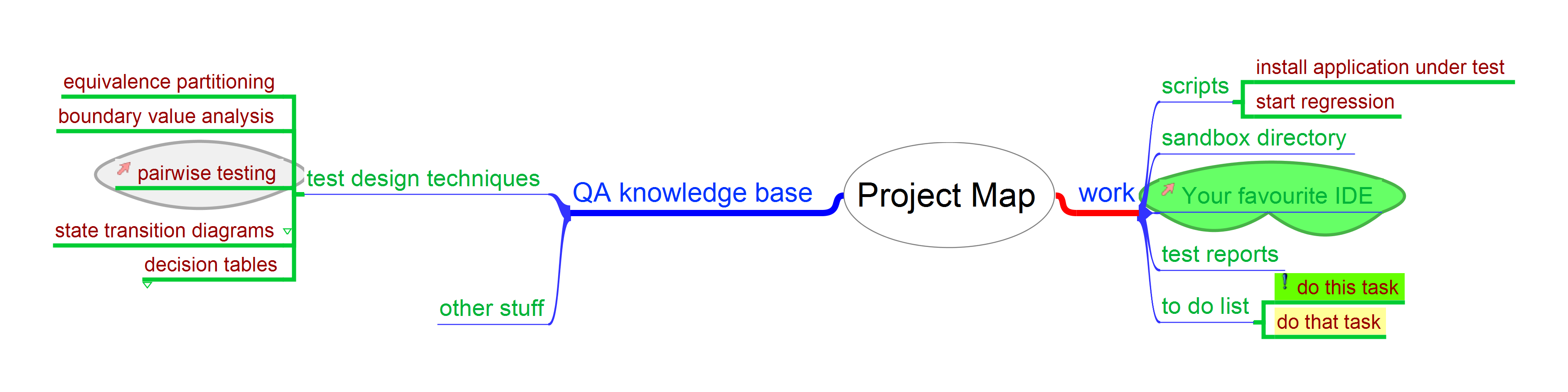
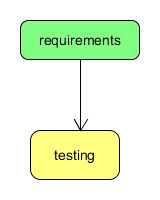
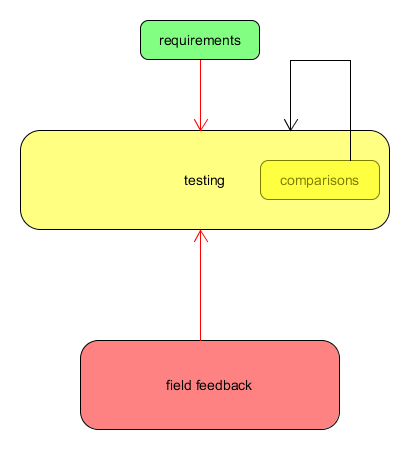
<?xml version="1.0"?>
<TestCases system="State-Transition-Diagram">
<Function name="text_direction">
<TestCase id="0">
<Input type="Tab1_is_selected">
<Var name="createNewTab" value="true">
<Has name="command" value="tab#LP#new2#RP#*isOpened#LP##RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
<Var name="select2Tab" value="NA"/>
<Var name="write1Tab" value="NA"/>
<Var name="changeTextDirectionToRTL1" value="NA"/>
<Var name="changeTextDirectionToLTR1" value="NA"/>
</Input>
<Input type="Tab2_is_selected">
<Var name="deleteTab" value="true">
<Has name="command" value="tab#LP#new2#RP#*isClosed#LP##RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
<Var name="select1Tab" value="NA"/>
<Var name="write2Tab" value="NA">
<Has name="command" value="tab#LP#new2#RP#*isWritten#LP##DQ#tab2text#DQ##RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
<Var name="changeTextDirectionToRTL2" value="NA"/>
<Var name="changeTextDirectionToLTR2" value="NA"/>
</Input>
</TestCase>
<TestCase id="1">
<Input type="Tab1_is_selected">
<Var name="createNewTab" value="true">
<Has name="command" value="tab#LP#new2#RP#*isOpened#LP##RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
<Var name="select2Tab" value="NA"/>
<Var name="write1Tab" value="NA"/>
<Var name="changeTextDirectionToRTL1" value="NA"/>
<Var name="changeTextDirectionToLTR1" value="NA"/>
</Input>
<Input type="Tab2_is_selected">
<Var name="deleteTab" value="false"/>
<Var name="select1Tab" value="false"/>
<Var name="write2Tab" value="true">
<Has name="command" value="tab#LP#new2#RP#*isWritten#LP##DQ#tab2text#DQ##RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
<Var name="changeTextDirectionToRTL2" value="true">
<Has name="command" value="textDirectionIsChanged#LP#RTL#RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
<Var name="changeTextDirectionToLTR2" value="true">
<Has name="command" value="textDirectionIsChanged#LP#LTR#RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
</Input>
</TestCase>
<TestCase id="2">
<Input type="Tab1_is_selected">
<Var name="createNewTab" value="true">
<Has name="command" value="tab#LP#new2#RP#*isOpened#LP##RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
<Var name="select2Tab" value="NA"/>
<Var name="write1Tab" value="NA"/>
<Var name="changeTextDirectionToRTL1" value="NA"/>
<Var name="changeTextDirectionToLTR1" value="NA"/>
</Input>
<Input type="Tab2_is_selected">
<Var name="deleteTab" value="NA"/>
<Var name="select1Tab" value="true">
<Has name="command" value="tab#LP#new1#RP#*isSelected#LP##RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
<Var name="write2Tab" value="NA">
<Has name="command" value="tab#LP#new2#RP#*isWritten#LP##DQ#tab2text#DQ##RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
<Var name="changeTextDirectionToRTL2" value="NA"/>
<Var name="changeTextDirectionToLTR2" value="NA"/>
</Input>
</TestCase>
<TestCase id="3">
<Input type="Tab1_is_selected">
<Var name="createNewTab" value="true">
<Has name="command" value="tab#LP#new2#RP#*isOpened#LP##RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
<Var name="select2Tab" value="NA"/>
<Var name="write1Tab" value="NA"/>
<Var name="changeTextDirectionToRTL1" value="NA"/>
<Var name="changeTextDirectionToLTR1" value="NA"/>
</Input>
<Input type="Tab2_is_selected">
<Var name="deleteTab" value="false"/>
<Var name="select1Tab" value="false"/>
<Var name="write2Tab" value="false">
<Has name="command" value="tab#LP#new2#RP#*isWritten#LP##DQ#tab2text#DQ##RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
<Var name="changeTextDirectionToRTL2" value="false"/>
<Var name="changeTextDirectionToLTR2" value="false"/>
</Input>
</TestCase>
<TestCase id="4">
<Input type="Tab1_is_selected">
<Var name="createNewTab" value="false"/>
<Var name="select2Tab" value="false"/>
<Var name="write1Tab" value="true">
<Has name="command" value="tab#LP#new1#RP#*isWritten#LP##DQ#tab1text#DQ##RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
<Var name="changeTextDirectionToRTL1" value="true">
<Has name="command" value="textDirectionIsChanged#LP#RTL#RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
<Var name="changeTextDirectionToLTR1" value="true">
<Has name="command" value="textDirectionIsChanged#LP#LTR#RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
</Input>
<Input type="Tab2_is_selected">
<Var name="deleteTab" value="NA"/>
<Var name="select1Tab" value="NA"/>
<Var name="write2Tab" value="NA">
<Has name="command" value="tab#LP#new2#RP#*isWritten#LP##DQ#tab2text#DQ##RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
<Var name="changeTextDirectionToRTL2" value="NA"/>
<Var name="changeTextDirectionToLTR2" value="NA"/>
</Input>
</TestCase>
<TestCase id="5">
<Input type="Tab1_is_selected">
<Var name="createNewTab" value="false"/>
<Var name="select2Tab" value="false"/>
<Var name="write1Tab" value="false"/>
<Var name="changeTextDirectionToRTL1" value="false"/>
<Var name="changeTextDirectionToLTR1" value="false"/>
</Input>
<Input type="Tab2_is_selected">
<Var name="deleteTab" value="NA"/>
<Var name="select1Tab" value="NA"/>
<Var name="write2Tab" value="NA">
<Has name="command" value="tab#LP#new2#RP#*isWritten#LP##DQ#tab2text#DQ##RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
<Var name="changeTextDirectionToRTL2" value="NA"/>
<Var name="changeTextDirectionToLTR2" value="NA"/>
</Input>
</TestCase>
<TestCase id="6">
<Input type="Tab1_is_selected">
<Var name="createNewTab" value="NA"/>
<Var name="select2Tab" value="true">
<Has name="command" value="tab#LP#new2#RP#*isOpened#LP##RP#*WHEN#LP##RP#*tab#LP#new1#RP#*isSelected#LP##RP#*WHEN#LP##RP#*tab#LP#new2#RP#*isSelected#LP##RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
<Var name="write1Tab" value="NA"/>
<Var name="changeTextDirectionToRTL1" value="NA"/>
<Var name="changeTextDirectionToLTR1" value="NA"/>
</Input>
<Input type="Tab2_is_selected">
<Var name="deleteTab" value="true">
<Has name="command" value="tab#LP#new2#RP#*isClosed#LP##RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
<Var name="select1Tab" value="NA"/>
<Var name="write2Tab" value="NA">
<Has name="command" value="tab#LP#new2#RP#*isWritten#LP##DQ#tab2text#DQ##RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
<Var name="changeTextDirectionToRTL2" value="NA"/>
<Var name="changeTextDirectionToLTR2" value="NA"/>
</Input>
</TestCase>
<TestCase id="7">
<Input type="Tab1_is_selected">
<Var name="createNewTab" value="NA"/>
<Var name="select2Tab" value="true">
<Has name="command" value="tab#LP#new2#RP#*isOpened#LP##RP#*WHEN#LP##RP#*tab#LP#new1#RP#*isSelected#LP##RP#*WHEN#LP##RP#*tab#LP#new2#RP#*isSelected#LP##RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
<Var name="write1Tab" value="NA"/>
<Var name="changeTextDirectionToRTL1" value="NA"/>
<Var name="changeTextDirectionToLTR1" value="NA"/>
</Input>
<Input type="Tab2_is_selected">
<Var name="deleteTab" value="false"/>
<Var name="select1Tab" value="false"/>
<Var name="write2Tab" value="true">
<Has name="command" value="tab#LP#new2#RP#*isWritten#LP##DQ#tab2text#DQ##RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
<Var name="changeTextDirectionToRTL2" value="true">
<Has name="command" value="textDirectionIsChanged#LP#RTL#RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
<Var name="changeTextDirectionToLTR2" value="true">
<Has name="command" value="textDirectionIsChanged#LP#LTR#RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
</Input>
</TestCase>
<TestCase id="8">
<Input type="Tab1_is_selected">
<Var name="createNewTab" value="NA"/>
<Var name="select2Tab" value="true">
<Has name="command" value="tab#LP#new2#RP#*isOpened#LP##RP#*WHEN#LP##RP#*tab#LP#new1#RP#*isSelected#LP##RP#*WHEN#LP##RP#*tab#LP#new2#RP#*isSelected#LP##RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
<Var name="write1Tab" value="NA"/>
<Var name="changeTextDirectionToRTL1" value="NA"/>
<Var name="changeTextDirectionToLTR1" value="NA"/>
</Input>
<Input type="Tab2_is_selected">
<Var name="deleteTab" value="NA"/>
<Var name="select1Tab" value="true">
<Has name="command" value="tab#LP#new1#RP#*isSelected#LP##RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
<Var name="write2Tab" value="NA">
<Has name="command" value="tab#LP#new2#RP#*isWritten#LP##DQ#tab2text#DQ##RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
<Var name="changeTextDirectionToRTL2" value="NA"/>
<Var name="changeTextDirectionToLTR2" value="NA"/>
</Input>
</TestCase>
<TestCase id="9">
<Input type="Tab1_is_selected">
<Var name="createNewTab" value="NA"/>
<Var name="select2Tab" value="true">
<Has name="command" value="tab#LP#new2#RP#*isOpened#LP##RP#*WHEN#LP##RP#*tab#LP#new1#RP#*isSelected#LP##RP#*WHEN#LP##RP#*tab#LP#new2#RP#*isSelected#LP##RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
<Var name="write1Tab" value="NA"/>
<Var name="changeTextDirectionToRTL1" value="NA"/>
<Var name="changeTextDirectionToLTR1" value="NA"/>
</Input>
<Input type="Tab2_is_selected">
<Var name="deleteTab" value="false"/>
<Var name="select1Tab" value="false"/>
<Var name="write2Tab" value="false">
<Has name="command" value="tab#LP#new2#RP#*isWritten#LP##DQ#tab2text#DQ##RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
<Var name="changeTextDirectionToRTL2" value="false"/>
<Var name="changeTextDirectionToLTR2" value="false"/>
</Input>
</TestCase>
<TestCase id="10">
<Input type="Tab1_is_selected">
<Var name="createNewTab" value="false"/>
<Var name="select2Tab" value="false"/>
<Var name="write1Tab" value="true">
<Has name="command" value="tab#LP#new1#RP#*isWritten#LP##DQ#tab1text#DQ##RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
<Var name="changeTextDirectionToRTL1" value="false"/>
<Var name="changeTextDirectionToLTR1" value="false"/>
</Input>
<Input type="Tab2_is_selected">
<Var name="deleteTab" value="NA"/>
<Var name="select1Tab" value="NA"/>
<Var name="write2Tab" value="NA">
<Has name="command" value="tab#LP#new2#RP#*isWritten#LP##DQ#tab2text#DQ##RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
<Var name="changeTextDirectionToRTL2" value="NA"/>
<Var name="changeTextDirectionToLTR2" value="NA"/>
</Input>
</TestCase>
<TestCase id="11">
<Input type="Tab1_is_selected">
<Var name="createNewTab" value="false"/>
<Var name="select2Tab" value="false"/>
<Var name="write1Tab" value="false"/>
<Var name="changeTextDirectionToRTL1" value="true">
<Has name="command" value="textDirectionIsChanged#LP#RTL#RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
<Var name="changeTextDirectionToLTR1" value="true">
<Has name="command" value="textDirectionIsChanged#LP#LTR#RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
</Input>
<Input type="Tab2_is_selected">
<Var name="deleteTab" value="NA"/>
<Var name="select1Tab" value="NA"/>
<Var name="write2Tab" value="NA">
<Has name="command" value="tab#LP#new2#RP#*isWritten#LP##DQ#tab2text#DQ##RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
<Var name="changeTextDirectionToRTL2" value="NA"/>
<Var name="changeTextDirectionToLTR2" value="NA"/>
</Input>
</TestCase>
<TestCase id="12">
<Input type="Tab1_is_selected">
<Var name="createNewTab" value="false"/>
<Var name="select2Tab" value="false"/>
<Var name="write1Tab" value="true">
<Has name="command" value="tab#LP#new1#RP#*isWritten#LP##DQ#tab1text#DQ##RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
<Var name="changeTextDirectionToRTL1" value="true">
<Has name="command" value="textDirectionIsChanged#LP#RTL#RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
<Var name="changeTextDirectionToLTR1" value="false"/>
</Input>
<Input type="Tab2_is_selected">
<Var name="deleteTab" value="NA"/>
<Var name="select1Tab" value="NA"/>
<Var name="write2Tab" value="NA">
<Has name="command" value="tab#LP#new2#RP#*isWritten#LP##DQ#tab2text#DQ##RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
<Var name="changeTextDirectionToRTL2" value="NA"/>
<Var name="changeTextDirectionToLTR2" value="NA"/>
</Input>
</TestCase>
<TestCase id="13">
<Input type="Tab1_is_selected">
<Var name="createNewTab" value="false"/>
<Var name="select2Tab" value="false"/>
<Var name="write1Tab" value="true">
<Has name="command" value="tab#LP#new1#RP#*isWritten#LP##DQ#tab1text#DQ##RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
<Var name="changeTextDirectionToRTL1" value="false"/>
<Var name="changeTextDirectionToLTR1" value="true">
<Has name="command" value="textDirectionIsChanged#LP#LTR#RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
</Input>
<Input type="Tab2_is_selected">
<Var name="deleteTab" value="NA"/>
<Var name="select1Tab" value="NA"/>
<Var name="write2Tab" value="NA">
<Has name="command" value="tab#LP#new2#RP#*isWritten#LP##DQ#tab2text#DQ##RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
<Var name="changeTextDirectionToRTL2" value="NA"/>
<Var name="changeTextDirectionToLTR2" value="NA"/>
</Input>
</TestCase>
<TestCase id="14">
<Input type="Tab1_is_selected">
<Var name="createNewTab" value="true">
<Has name="command" value="tab#LP#new2#RP#*isOpened#LP##RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
<Var name="select2Tab" value="NA"/>
<Var name="write1Tab" value="NA"/>
<Var name="changeTextDirectionToRTL1" value="NA"/>
<Var name="changeTextDirectionToLTR1" value="NA"/>
</Input>
<Input type="Tab2_is_selected">
<Var name="deleteTab" value="false"/>
<Var name="select1Tab" value="false"/>
<Var name="write2Tab" value="true">
<Has name="command" value="tab#LP#new2#RP#*isWritten#LP##DQ#tab2text#DQ##RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
<Var name="changeTextDirectionToRTL2" value="false"/>
<Var name="changeTextDirectionToLTR2" value="false"/>
</Input>
</TestCase>
<TestCase id="15">
<Input type="Tab1_is_selected">
<Var name="createNewTab" value="NA"/>
<Var name="select2Tab" value="true">
<Has name="command" value="tab#LP#new2#RP#*isOpened#LP##RP#*WHEN#LP##RP#*tab#LP#new1#RP#*isSelected#LP##RP#*WHEN#LP##RP#*tab#LP#new2#RP#*isSelected#LP##RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
<Var name="write1Tab" value="NA"/>
<Var name="changeTextDirectionToRTL1" value="NA"/>
<Var name="changeTextDirectionToLTR1" value="NA"/>
</Input>
<Input type="Tab2_is_selected">
<Var name="deleteTab" value="false"/>
<Var name="select1Tab" value="false"/>
<Var name="write2Tab" value="false">
<Has name="command" value="tab#LP#new2#RP#*isWritten#LP##DQ#tab2text#DQ##RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
<Var name="changeTextDirectionToRTL2" value="true">
<Has name="command" value="textDirectionIsChanged#LP#RTL#RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
<Var name="changeTextDirectionToLTR2" value="true">
<Has name="command" value="textDirectionIsChanged#LP#LTR#RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
</Input>
</TestCase>
<TestCase id="16">
<Input type="Tab1_is_selected">
<Var name="createNewTab" value="true">
<Has name="command" value="tab#LP#new2#RP#*isOpened#LP##RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
<Var name="select2Tab" value="NA"/>
<Var name="write1Tab" value="NA"/>
<Var name="changeTextDirectionToRTL1" value="NA"/>
<Var name="changeTextDirectionToLTR1" value="NA"/>
</Input>
<Input type="Tab2_is_selected">
<Var name="deleteTab" value="false"/>
<Var name="select1Tab" value="false"/>
<Var name="write2Tab" value="false">
<Has name="command" value="tab#LP#new2#RP#*isWritten#LP##DQ#tab2text#DQ##RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
<Var name="changeTextDirectionToRTL2" value="true">
<Has name="command" value="textDirectionIsChanged#LP#RTL#RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
<Var name="changeTextDirectionToLTR2" value="false"/>
</Input>
</TestCase>
<TestCase id="17">
<Input type="Tab1_is_selected">
<Var name="createNewTab" value="NA"/>
<Var name="select2Tab" value="true">
<Has name="command" value="tab#LP#new2#RP#*isOpened#LP##RP#*WHEN#LP##RP#*tab#LP#new1#RP#*isSelected#LP##RP#*WHEN#LP##RP#*tab#LP#new2#RP#*isSelected#LP##RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
<Var name="write1Tab" value="NA"/>
<Var name="changeTextDirectionToRTL1" value="NA"/>
<Var name="changeTextDirectionToLTR1" value="NA"/>
</Input>
<Input type="Tab2_is_selected">
<Var name="deleteTab" value="false"/>
<Var name="select1Tab" value="false"/>
<Var name="write2Tab" value="true">
<Has name="command" value="tab#LP#new2#RP#*isWritten#LP##DQ#tab2text#DQ##RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
<Var name="changeTextDirectionToRTL2" value="false"/>
<Var name="changeTextDirectionToLTR2" value="true">
<Has name="command" value="textDirectionIsChanged#LP#LTR#RP#"/>
<Has name="expected" value="notepad#LP##RP#*guiIsVisible#LP##RP#"/>
<Has name="gherkinType" value="WHEN"/>
</Var>
</Input>
</TestCase>
</Function>
</TestCases>